Using ESPHome to Automatically restart frozen cable modem
Part of the reason for developing my SB8200 monitor was to get to the bottom of some infrequent but regular outages.
To make a long story short, the LAG implementation on the modem seems to have some issues. A quick google will return many complaint threads detailing issues with the modem regularly locking up all traffic stopping. More annoyingly, these reports date back years and allege that later revisions of the firmware might fix the issue for good.
My ISP is evil and doesn’t give me a way to check for or manually update the firmware on device.
As expected, their stance is that all my issues will go away if I rent their modem and let them up-sell me a faster service tier, though 🙄.
When the modem falls over, it’s pretty sudden; things will be fine one moment and then no traffic flows the next. The exact timing seems to vary a bit, but the average time between lockups is about 10 days with very little variance.
I’ve been “lucky” in the sense that most of these lockups have happened during the day while I was at home; I could notice the issue, triage and fix it pretty quickly. My dashboards have at most 300 seconds of down time or so.
There’s only so much luck to go around, though; what happens when I’m out of the house?I’ve been thinking about how to automate the process of restarting the modem and this is what I came up with.
The “fix”
My modem is powered through a Sonoff S31 plug running ESPHome.
Every 10 seconds, the S31 tries to fetch the modem’s http interface using the http_request component.
If - after 2 seconds - the modem doesn’t respond, a counter is incremented.
Once the counter reaches 5 consecutive failures, the power to the modem is briefly interrupted just as if I had unplugged it, counted to 10 and plugged it back in.
To make this bit of ESPHome configuration re-usable, I’ve packaged up the functionality into a pair of standalone files that can be included into an existing ESPHome configuration.
Documentation for why/how things work has been put in the comments of each file to aid understanding.
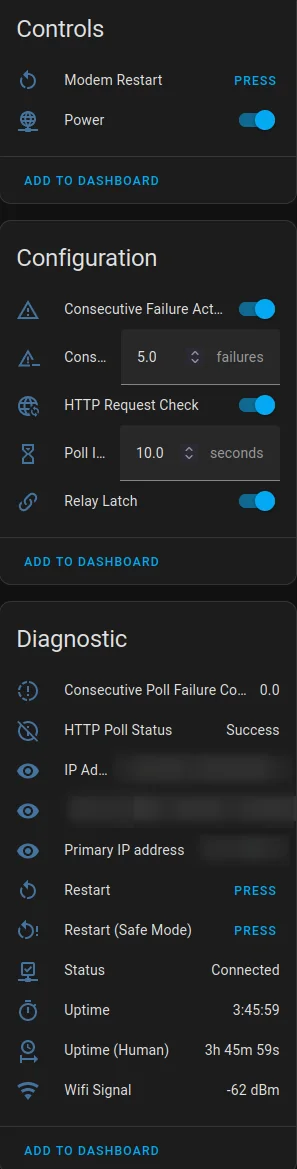
How the S31 powering modem appears in Home Assistant
base.yaml
This implements 95% of the logic and everything that’s not implementation specific:
substitutions:
# How many seconds between http requests
poll_interval_seconds: "10"
# How many failed requests before we take action
# If polling happens every 10 seconds and runs for at most 2 seconds then
# 5 failures in a row would mean that the host has been in a failed state for
# somewhere between 50 and 60 seconds before we take action.
consecutive_failure_threshold: "5"
# How many polls to wait for until action can be taken again
lockout_ticks_count: "20"
globals:
# How many seconds between checking the remote host
- id: glbl_http_poll_interval_ticks
type: int
restore_value: yes
initial_value: ${poll_interval_seconds}
# Not clear if script execution is blocked while the http request is in flight.
# It appears to be, so I might be able to safely remove this?
- id: _glbl_http_poll_request_in_flight
type: bool
restore_value: no
initial_value: "false"
# Lockout/cool-down prevents a failed result from immediately triggering another cycle
# E.g.: if the poll target is down and we power cycle it and then immediately check... it won't respond
# which will mean another power cycle ...
- id: _glbl_http_poll_lockout_ticks
type: int
restore_value: yes
initial_value: ${lockout_ticks_count}
# Need to keep track of the number of ticks since we last took the failure action
- id: _glbl_http_poll_ticks_since_last_failure_action
type: int
restore_value: no
initial_value: "0"
# Monotonically increasing counter
- id: _glbl_http_poll_ticks
type: int
restore_value: no
initial_value: "0"
# How many failures have we had?
- id: _glbl_http_poll_failures_count
type: int
restore_value: no
initial_value: "0"
# How many failures before we do something?
- id: glbl_http_poll_failures_threshold
type: int
restore_value: no
initial_value: ${consecutive_failure_threshold}
# Allows for disconnecting consecutive failure action if needed.
- id: _glbl_http_poll_consecutive_failure_action_enabled
type: bool
restore_value: no
initial_value: "true"
# Expose the current state of the poll/lockout timer
text_sensor:
- name: "HTTP Poll Status"
id: txt_operation_mode
platform: template
icon: "mdi:information-off-outline"
entity_category: "diagnostic"
# Will be called to update as necessary from other components
update_interval: never
lambda: |
// This lambda function should never be called / we should never update the text sensor this way
return {"Unknown"};
# Expose the current success/failure counts for stats
sensor:
- name: "Consecutive Poll Failure Count"
platform: template
id: s_consecutive_poll_failure_count
icon: "mdi:progress-alert"
entity_category: "diagnostic"
lambda: |-
if (id(_glbl_http_poll_failures_count)) {
return id(_glbl_http_poll_failures_count);
} else {
return 0.0;
}
# Will be called to update as necessary from other components
update_interval: never
##
# Allow tweaking the poll interval and failure threshold via Home Assistant
# See: https://esphome.io/components/number/template.html
##
number:
- name: "Poll Interval"
id: num_poll_interval
platform: template
icon: "mdi:timer-sand"
entity_category: "config"
unit_of_measurement: seconds
mode: box
min_value: 2
max_value: 120
step: 1
lambda: |-
return (int) id(glbl_http_poll_interval_ticks);
set_action:
then:
# Store the val
- globals.set:
id: glbl_http_poll_interval_ticks
value: !lambda |-
return (int) x;
- name: "Consecutive Failure Threshold"
id: num_consecutive_failure_threshold
platform: template
icon: "mdi:alert-minus-outline"
entity_category: "config"
unit_of_measurement: failures
mode: box
min_value: 2
max_value: 10
step: 1
lambda: |-
return (int) id(glbl_http_poll_failures_threshold);
set_action:
then:
# Store the val
- globals.set:
id: glbl_http_poll_failures_threshold
value: !lambda |-
return (int) x;
switch:
# A global arm/disarm switch for the http poll
- name: "HTTP Request Check"
platform: template
id: sw_http_request
icon: "mdi:web-sync"
entity_category: "config"
# It's OK to have this set to ON at boot since we immediately go into lockout mode before we start polling
restore_mode: RESTORE_DEFAULT_ON
# This way we don't need to create a global for the state
optimistic: true
on_turn_on:
- script.execute: _on_http_poll_turned_on
on_turn_off:
- script.execute: _on_http_poll_turned_off
# In addition to polling, also gate the actual consecutive failure action.
# This way, action can be disabled without disabling the polling itself; useful for testing polling
# or just gathering stats about how often the poll fails...
##
- name: "Consecutive Failure Action Enable"
platform: template
id: sw_cons_failure_action
icon: "mdi:alert-outline"
entity_category: "config"
# It's OK to have this set to ON at boot since we immediately go into lockout mode before we start polling
restore_mode: RESTORE_DEFAULT_ON
# This way we don't need to create a global for the state
lambda: |-
return id(_glbl_http_poll_consecutive_failure_action_enabled);
turn_on_action:
- globals.set:
id: _glbl_http_poll_consecutive_failure_action_enabled
value: "true"
turn_off_action:
- globals.set:
id: _glbl_http_poll_consecutive_failure_action_enabled
value: "false"
script:
# When polling starts back up, we have some variable initialization to do
- id: _on_http_poll_turned_on
mode: single
then:
- lambda: |-
id(_glbl_http_poll_ticks) = 0;
id(_glbl_http_poll_ticks_since_last_failure_action) = 0;
id(_glbl_http_poll_failures_count) = 0;
id(_glbl_http_poll_request_in_flight) = false;
id(txt_operation_mode).publish_state("Armed");
id(_http_poll_tick).execute();
# When polling function is turned off, there's a few things to clean up
- id: _on_http_poll_turned_off
mode: single
then:
- lambda: |-
id(_glbl_http_poll_ticks) = 0;
id(_glbl_http_poll_ticks_since_last_failure_action) = 0;
id(_glbl_http_poll_request_in_flight) = false;
id(txt_operation_mode).publish_state("Disarmed");
id(_do_poll).stop();
id(_http_poll_tick).stop();
# What do we do when we get a 200 response?
- id: _on_http_poll_ok
mode: single
then:
# Poll was OK, indicate status and reset the _glbl_http_poll_failures_count
- lambda: |-
auto const static TAG = "_on_http_poll_ok";
ESP_LOGD(TAG, "Poll OK. Resetting failure count.");
id(_glbl_http_poll_failures_count) = 0;
id(s_consecutive_poll_failure_count).update();
id(txt_operation_mode).publish_state("Success");
# What do we do when we get a non-200 response?
- id: _on_http_poll_failure
mode: single
then:
# Disable timer, have the text sensor update
- lambda: |-
auto const static TAG = "_on_http_poll_failure";
// Count and publish
id(_glbl_http_poll_failures_count)++;
id(s_consecutive_poll_failure_count).update();
id(txt_operation_mode).publish_state("Failure");
ESP_LOGW(TAG, "Failures: %i, Threshold: %i", id(_glbl_http_poll_failures_count), id(glbl_http_poll_failures_threshold));
if( id(_glbl_http_poll_failures_count) >= id(glbl_http_poll_failures_threshold) ) {
id(_on_http_poll_failure_threshold_met).execute();
}
# And when failure count reaches threshold, what do we do?
- id: _on_http_poll_failure_threshold_met
mode: single
then:
# Disable timer, have the text sensor update
- lambda: |-
auto const static TAG = "_on_http_poll_failure_threshold_met";
ESP_LOGE(TAG, "Consecutive failure threshold met!");
if (id(_glbl_http_poll_consecutive_failure_action_enabled)) {
ESP_LOGE(TAG, "Executing action!");
// User must provide _valid_ C++ code here to be substituted in at compile time
${failure_threshold_met_action}
} else {
ESP_LOGE(TAG, "Action disabled!");
}
// Reset the failure count
id(_glbl_http_poll_failures_count) = 0;
id(s_consecutive_poll_failure_count).update();
// Reset the time since last failure counter to enter lockout mode
id(_glbl_http_poll_ticks_since_last_failure_action) = 0;
- id: _do_poll
# DO NOT start a new run until the previous one completes!
mode: single
then:
# Tell the user we're polling
- lambda: |-
// Indicate we are now polling
id(txt_operation_mode).publish_state("Polling");
id(_glbl_http_poll_request_in_flight) = true;
# Fire off the http request
- http_request.get:
id: http_poll
url: ${http_url}
verify_ssl: false
# In testing, was able to confirm that this will be called even if there's an error.
# If failure occurred before HTTP could happen, status will be negative integer
##
# ESPHome does not permit defining lambda functions "externally"... but we can do this with scripts.
# To make this package as re-usable as possible, call into a `handle_on_response` script and expect the user
# to provide one at compile time.
##
on_response:
then:
- script.execute:
id: handle_on_response
status_code: !lambda |-
return status_code;
duration_ms: !lambda |-
return duration_ms;
- id: _http_poll_tick
# Start a new run after previous runs completes. This will happen until timer.stop() is called on us
##
mode: queued
max_runs: 0
then:
# A single 'tick' is 1 second long
- delay: 1s
- lambda: |-
/*
The "super loop" scheduler.
This script is called every second and is responsible for determining if it's time to poll the target.
*/
auto const static TAG = "lambda._http_poll_tick";
static int num_ticks = 0;
// Count this tick
id(_glbl_http_poll_ticks) += 1;
id(_glbl_http_poll_ticks_since_last_failure_action)++;
num_ticks = id(_glbl_http_poll_ticks);
// Are we supposed to be running at all?
if( !id(sw_http_request) ) {
ESP_LOGD(TAG, "Not running. sw_http_request: %i", id(sw_http_request).state);
id(_on_http_poll_turned_off).execute();
return;
}
// Check if there's already a request in flight.
// Note that there appears to be a yaml only way of checking if a script is already running?
// I can't find an API that allows me to do this ... so for now we have to keep track of this flag in a global bool.
if (id(_glbl_http_poll_request_in_flight)) {
ESP_LOGD(TAG, "Request in flight! Nothing to do...");
id(_on_http_poll_turned_off).execute();
return;
}
// We should be running and there is currently no request in flight... Are we in lockout?
if( id(_glbl_http_poll_ticks_since_last_failure_action) < id(_glbl_http_poll_lockout_ticks) ) {
ESP_LOGD(TAG, "In lockout! ticks_since_last_failure_action: %i, lockout_ticks: %i", id(_glbl_http_poll_ticks_since_last_failure_action), id(_glbl_http_poll_lockout_ticks));
// TODO: add the lockout time remaining to the text sensor?
id(txt_operation_mode).publish_state("Locked Out");
id(_http_poll_tick).execute();
return;
}
// We're not in lock out...Is it time to poll?
if( num_ticks % id(glbl_http_poll_interval_ticks) != 0 ) {
ESP_LOGD(TAG, "Not time to poll. num_ticks: %i, interval_ticks: %i", num_ticks, id(glbl_http_poll_interval_ticks));
id(txt_operation_mode).publish_state("Waiting");
} else {
ESP_LOGD(TAG, "Time to poll! num_ticks: %i, glbl_http_poll_interval_ticks: %i", num_ticks, id(glbl_http_poll_interval_ticks));
id(_do_poll).execute();
}
// re-schedule so we're called again in a second!
id(_http_poll_tick).execute();modem.yaml
This file is the “implementation specific” details that can’t be done in base.yaml.
packages:
base: !include
file: base.yaml
vars:
# Comcast does not permit users to change this address on their own modems... 😡
http_url: "http://192.168.100.1"
# When enough consecutive failures have been detected, this is what is "injected" into the
# `_on_http_poll_failure_threshold_met` script. It must be _valid_ c++ code or compilation will fail.
# Elsewhere in my main ESPHome configuration, I have button that triggers an automation to
# briefly cut and then restore power to effectively power cycle the modem.
# This code is the same as the user manually pressing that button.
failure_threshold_met_action: "id(btn_modem_restart).press();"
# In testing, the web server on modem does come up quickly but seems to go back down after
# ISP pushes their configuration down. Web server comes back up a few seconds later.
# Best to just wait a while for things to stabilize.
lockout_ticks_count: 120
# Note: not possible to have this defined in `base.yaml` and tweaked with !extend here
# See: https://github.com/esphome/issues/issues/5360
##
http_request:
id: http_poll
follow_redirects: true
timeout: 2s
# Note: omit this for ESP32 devices :)
esp8266_disable_ssl_support: true
# This is where a request result is classified into either a failure or success.
# It lives outside of the base package because each http server is different.
script:
- id: handle_on_response
parameters:
# status_code, duration_ms
status_code: int
duration_ms: int
then:
- lambda: |-
auto const static TAG = "_do_poll.on_response";
// Request is no longer in flight
id(_glbl_http_poll_request_in_flight) = false;
ESP_LOGD(TAG, "Response status: %d, Duration: %u ms", status_code, duration_ms);
// Nominally, 200/OK is the ONLY success condition but since modem uses 302 redirect to HTTPS
// and the ESP8266 does not support TLS, we can't follow the redirect to the 200/OK page and
// must consider the 302 redirect as a success as well.
switch( status_code ) {
case 200:
id(_on_http_poll_ok).execute();
break;
case 302:
id(_on_http_poll_ok).execute();
break;
default:
ESP_LOGW(TAG, "Response status: %d, Duration: %u ms", status_code, duration_ms);
id(_on_http_poll_failure).execute();
break;
}All together now
Hopefully it’s clear to see that modem.yaml wraps/includes base.yaml.
This is how modem.yaml is injected into the existing configuration that I have deployed on the S31 powering my modem.
# See: https://esphome.io/guides/configuration-types.html#packages
packages:
# Omitted: common packages for Network info, NTP, OTA, MQTT,
# relay/gpio and other device specific things... etc
# Add http polling configured for this specific application
http_poll: !include packages/http_poll/modem.yaml
logger:
# <...>
logs:
# ESPHome considers anything not 200/OK as a failure and will WARN about it.
# See: https://github.com/esphome/esphome/blob/38b7bed2faa522e7e065d8362d6ea0bcaf1c64d5/esphome/components/http_request/http_request.cpp#L92
# This is technically correct but results in log spam that is not useful to me.
# For my purposes, hearing anything back from the modem (302 or 200) counts as a success.
# Silence log spam by hiding all http_request log lines unless they're ERROR level
http_request: ERROR
button:
# Note: must not conflict with the button named "Restart" which reboots the ESP, not toggles the relay!
- name: "Modem Restart"
id: btn_modem_restart
platform: template
icon: "mdi:restart"
on_press:
- switch.turn_off: sw_relay_toggle
- delay: 15s
- switch.turn_on: sw_relay_toggle